
گزارش پدیدههایی مانند افراد بیشناسنامه، بازماندن کودکان از تحصیل و ترک تحصیل کودکان و نوجوانان در بعضی نقاط کشور مانند سیستان و بلوچستان و نمونههای دیگری مانند آن در سالهای اخیر، پرسشهایی کلیتر را درباره امکان وجود برخی تمایزهای نهادینه بین اقوام در افکار عمومی مطرح کرده است.
مطابق تحقیق مرکز پژوهشهای مجلس، تعداد کودکان بازمانده از تحصیل با ۱۷% افزایش نسبت به هفت سال قبل به ۹۱۱ هزار نفر در سال ۱۴۰۱ رسیده است و بیشترین تعداد آن در پنج استان سیستان و بلوچستان، خراسان رضوی، تهران، خوزستان و آذربایجان غربی اعلام شده است[۱]. در گزارش دیگری در همان سال رئیس سازمان ثبت احوال در سال ۱۴۰۱ پنج استانِ سیستان و بلوچستان، خراسان، گلستان، کرمان و آذربایجان غربی را دارای بیشترین افراد بیشناسنامه در سطح کشور معرفی کرده است[۲].
تفاوتهای سیستماتیک میان گروههای اجتماعی یکی از موضوعات مهم در علوم اجتماعی است. مطالعه این تفاوتها از آن رو اهمیت دارد که میتواند نمایانگر تبعیضهای ریشهدار در جوامع و حکومتها باشد. آیا تفاوت معناداری در شاخصهای توسعه انسانی در میان قومیتهای ایرانی وجود دارد؟ در کدام یک از شاخصهای توسعه چنین تمایزهایی وجود دارد؟ اگر چنین شکافهایی وجود دارد، آیا با گذشت زمان ترمیم شده یا افزایش یافته است؟
این مطالعه تلاش میکند تا با تمرکز بر آمار گویشوران زبانها و شاخص وضعیت سواد، فتح بابی برای بررسی روابط موجود بین شاخصهای توسعه انسانی و اقوام ایرانی باشد و فرضیهها و پرسشهایی را در اینباره طرح کند.
کمبود داده و دشواری تحقیق
مهمترین منبع دادههای جمعیتی در ایران سرشماریهای عمومی نفوس و مسکن است که از دهه ۳۰ شمسی تاکنون به صورت کموبیش منظم هر ده سال یک بار انجام شده و دادههای ارزشمندی را در اختیار پژوهشگران قرار داده است. اما اطلاعات قومیتها و مذاهب به ندرت مانند سایر دادههای سرشماری منتشر شده است[۳]. به همین سبب تحقیق درباره قومیت و رابطه آن با دیگر پدیدههای اجتماعی و اقتصادی همیشه با دشواری رو به رو بوده است.
یکی از معدود تحقیقاتی که با ارائۀ گویشوران زبانهای مختلف در دهستانها، توزیع جغرافیایی قومیتهای ایران را با استفاده از سرشماریهای مرکز آمار گزارش میکند و به صورت عمومی انتشار یافته پژوهش ایرانکارتو است که بر اساس دادههای سال ۱۳۶۵ انجام شده و در سال ۱۳۷۶ منتشر شده است[۴]. با توجه به این که شواهد چندانی مبنی بر تغییر عمده سکونتگاه اقوام ایرانی از آن زمان تاکنون در دست نیست، میتوان فرض کرد توزیعِ جغرافیاییِ درصد گویشوران اقوام در جمعیت روستایی ایران و تا حدی در کل جمعیت، در این مدت کموبیش بدون تغییر مانده و بنابراین همچنان میتوان در تحلیل قومیت از این دادهها استفاده کرد.
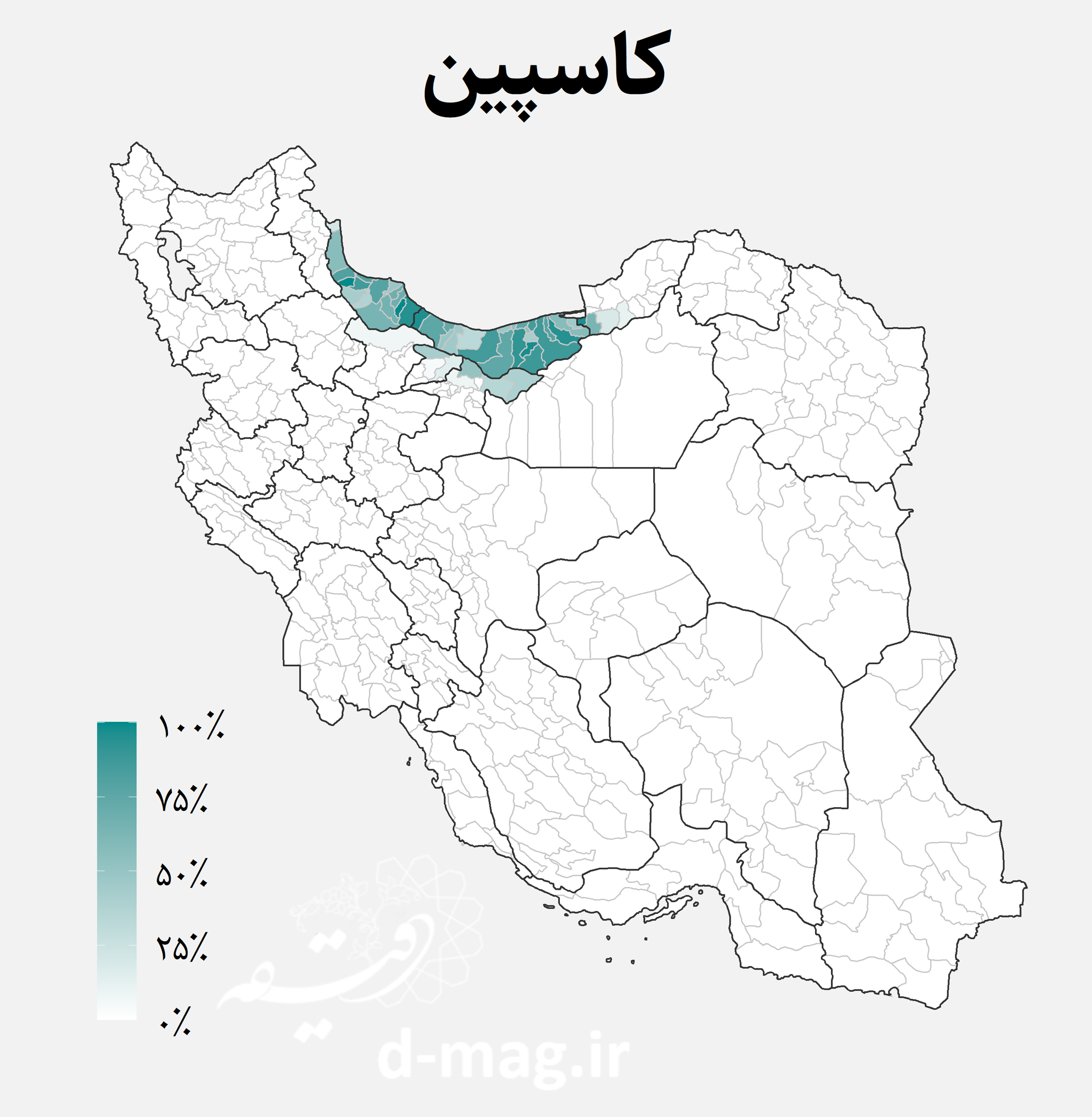
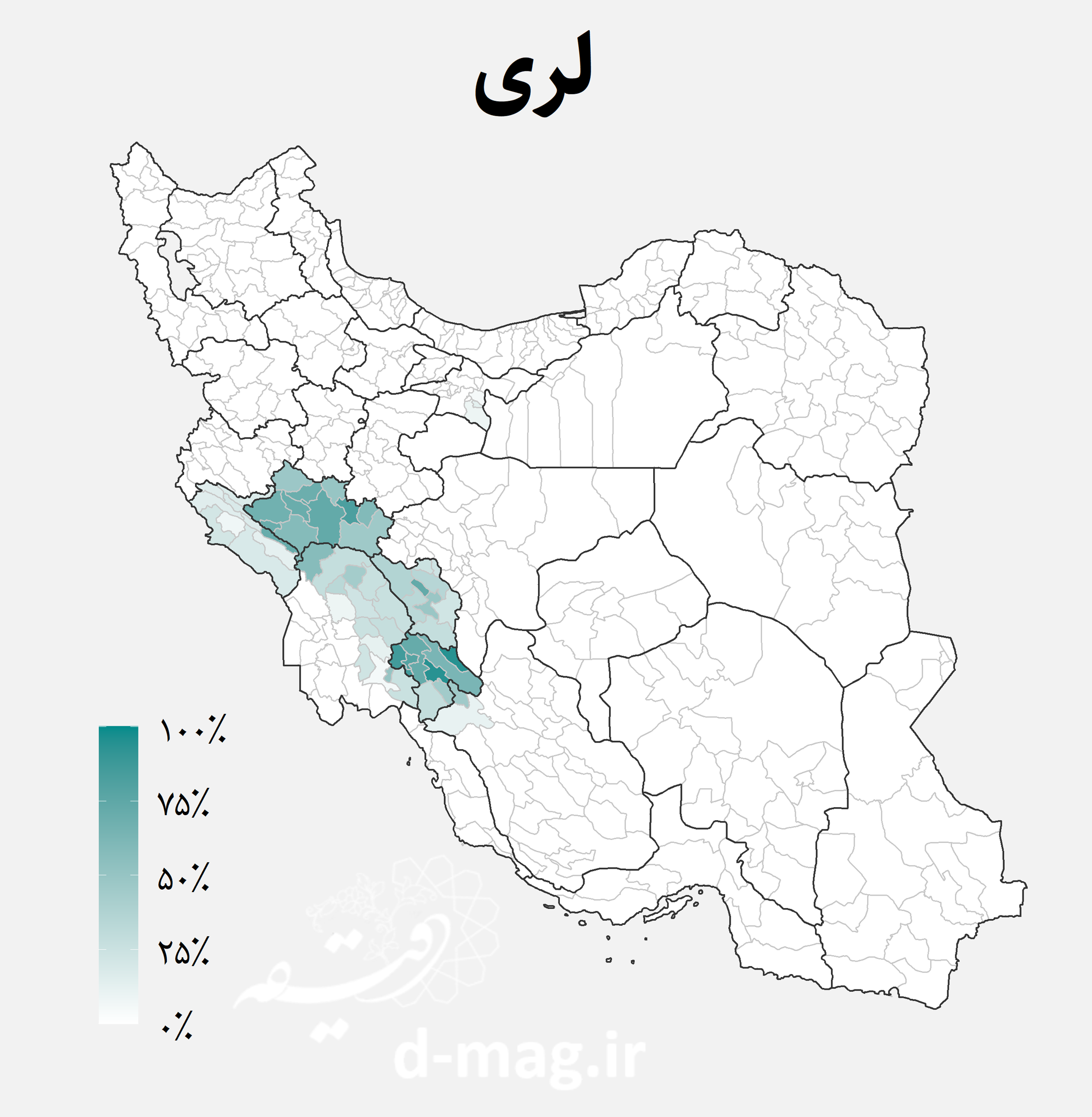
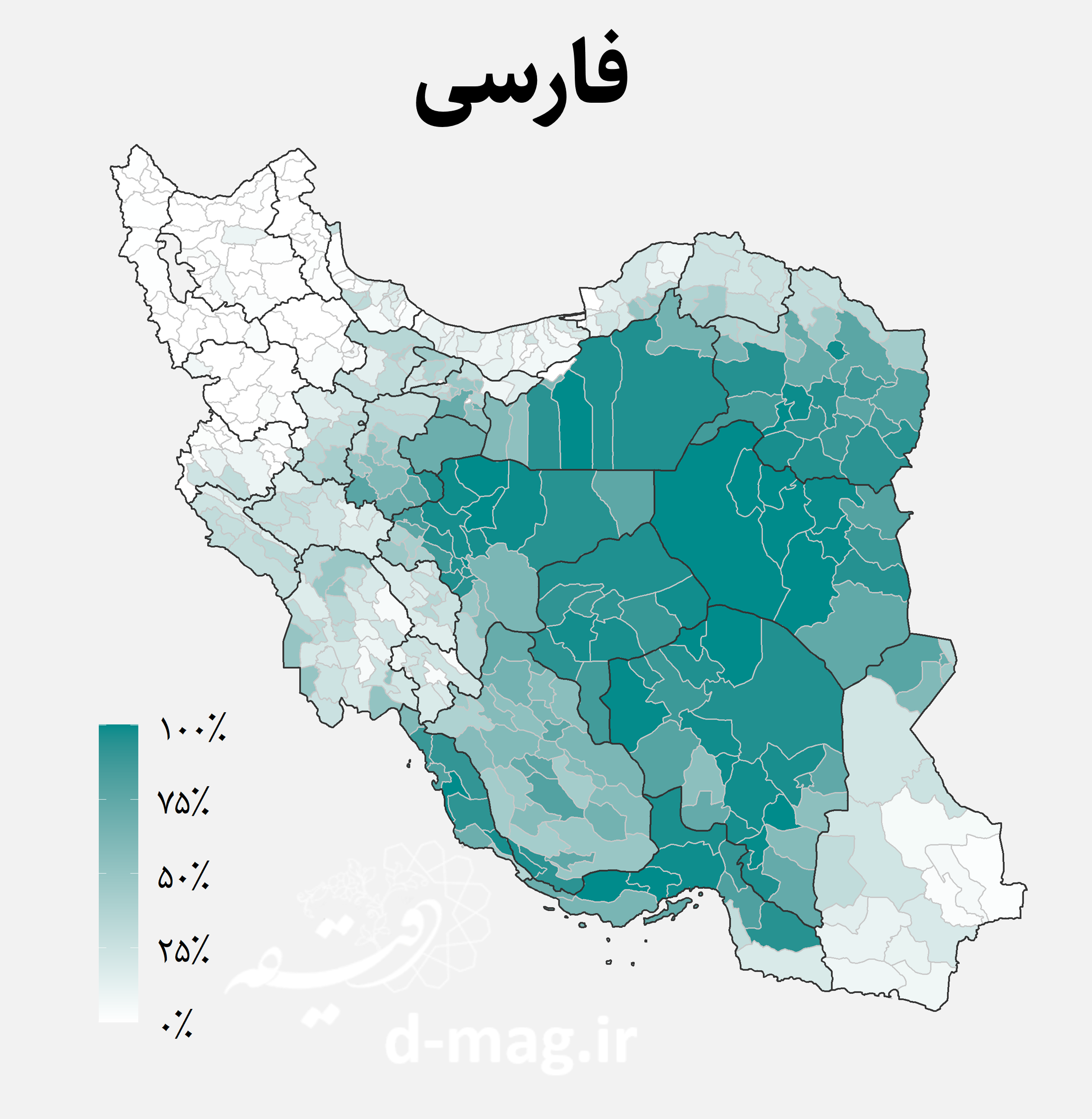
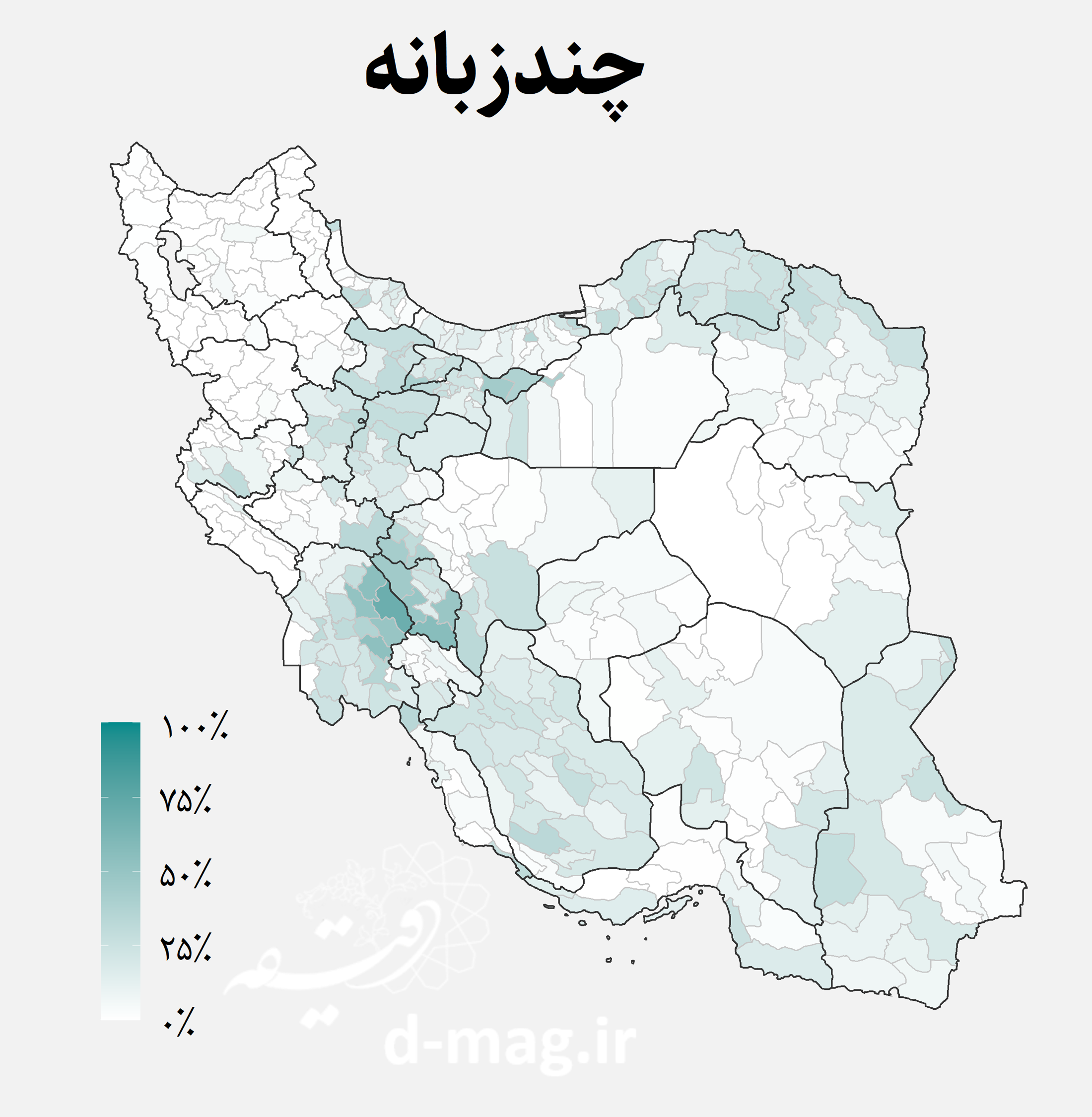
نقشه اقوام ایرانی
در تقسیمات کشوری، دهستان از کنار هم قرار گرفتن چند آبادی نزدیک به هم تشکیل میشود و افراد ساکن در آن را متعلق به جمعیت روستایی در نظر میگیرند. دهستانها و شهرها در کنار یکدیگر بخش را تشکیل میدهند و بخشها در کنار یکدیگر شهرستان را ایجاد میکنند.
در دادههای ایرانکارتو تعداد آبادیهای هر یک از دهستانها به تفکیکِ زبان غالب گویشوران آن گزارش شده است. این زبانها در هشت دسته زیر طبقهبندی شدهاند:
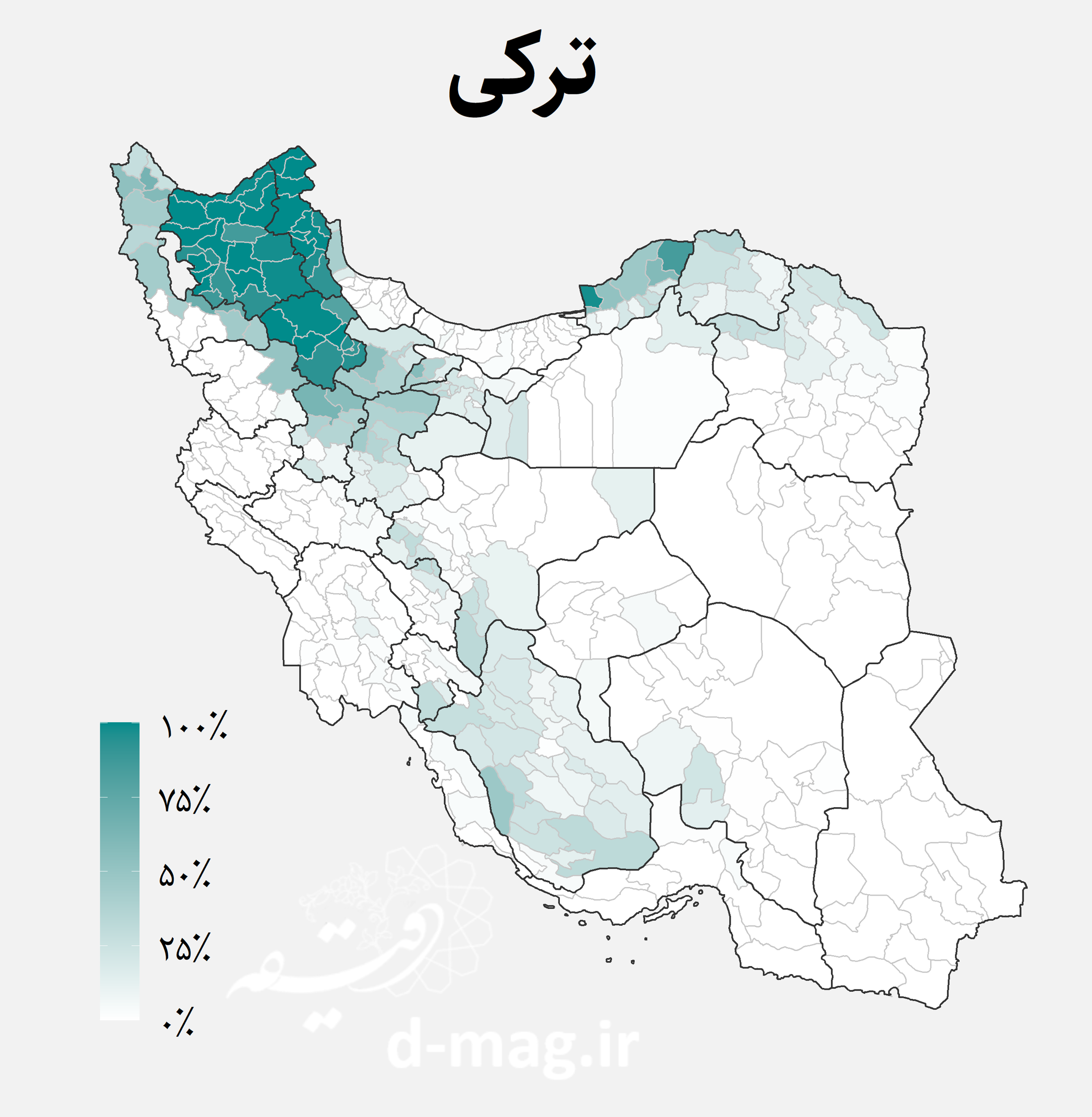
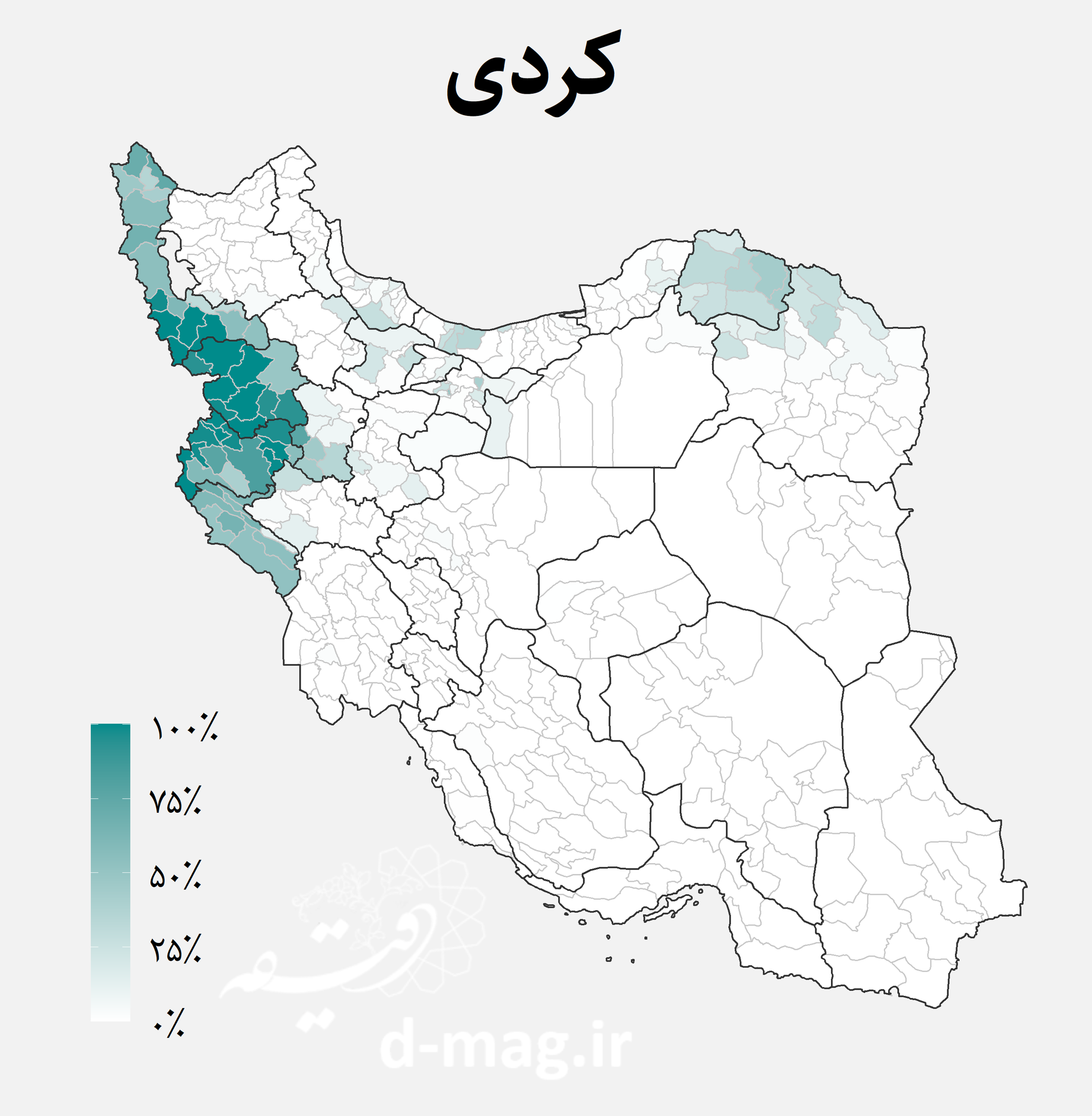
در این دادهها تعداد گویشوران هر یک از زبانها در آبادی گزارش نشده است. اما با توجه به زبان غالب آبادی میدانیم در هر دهستان چند آبادی به کدام زبان صحبت میکنند. اگر جمعیت آبادیها را یکسان فرض کنیم، میتوانیم تخمینی اولیه از جمعیت گویشوران هر زبان در هر دهستان بدست آوریم. سپس میتوان با تجمیع جمعیتهای به دست آمده، درصد گویشوران هر زبان را در میان روستانشینان هر شهرستان به دست آورد. نتیجه این محاسبات را در نقشههای زیر مشاهده کنید.
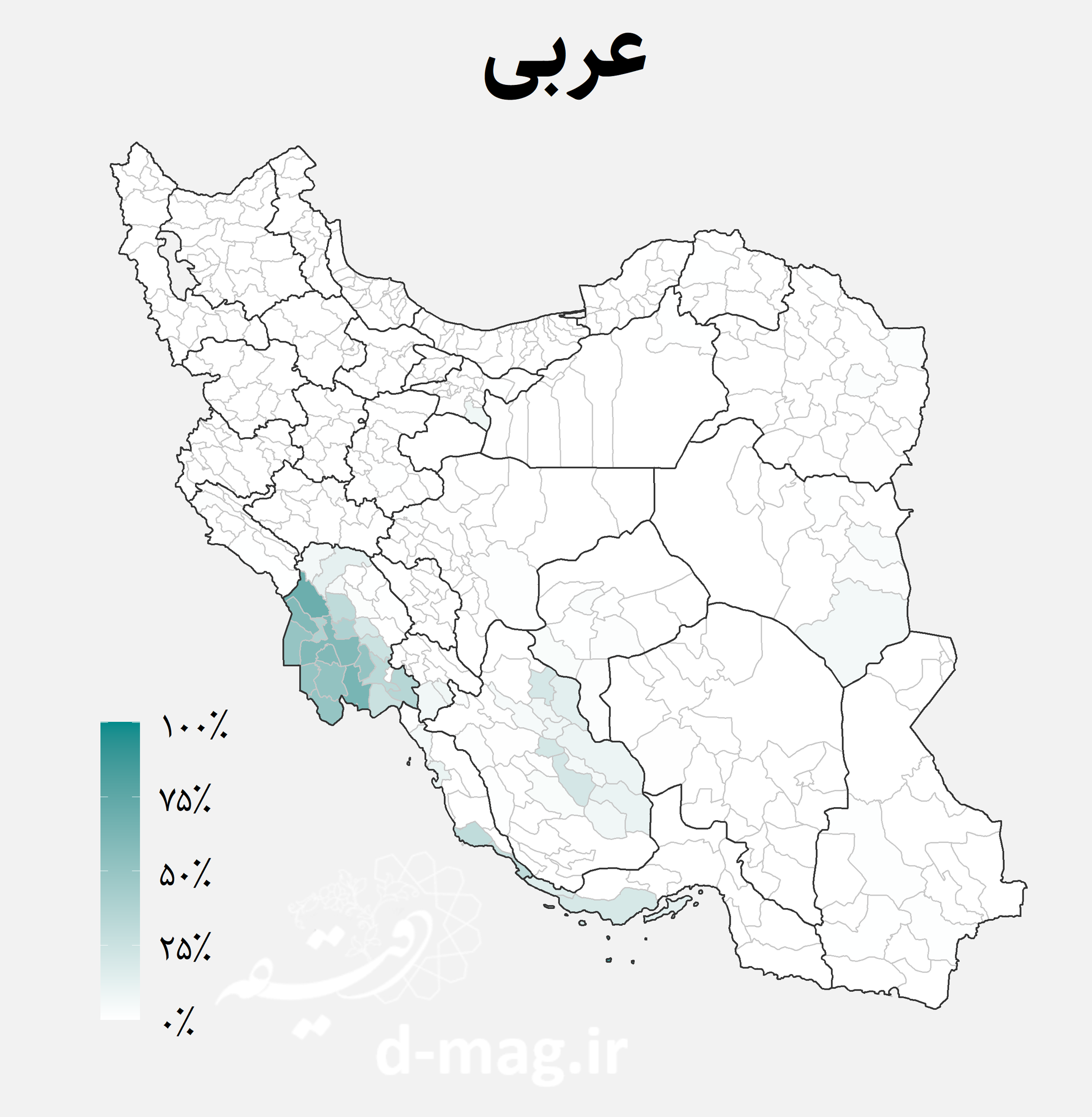
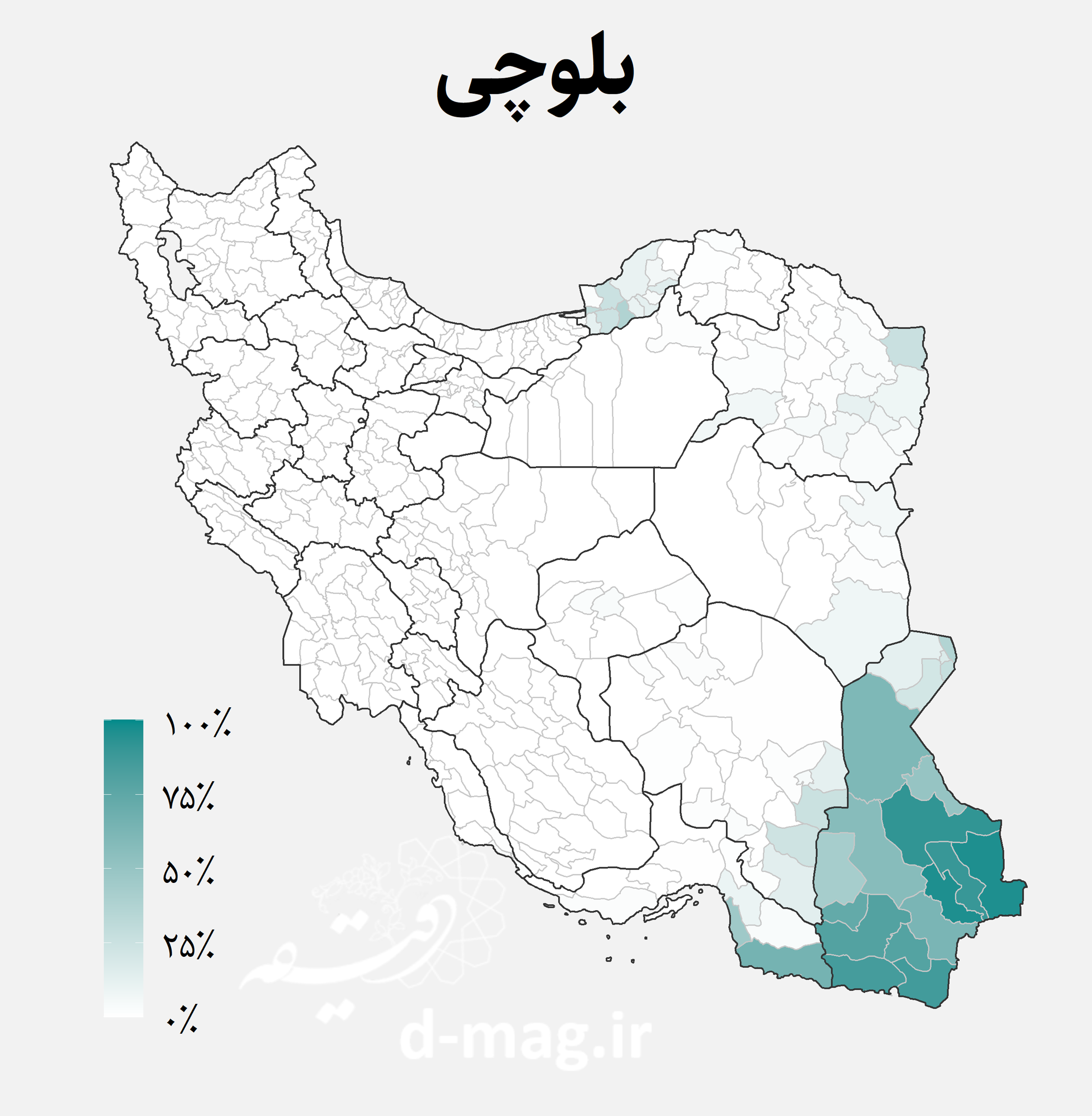
نقشههای فوق توزیع جغرافیایی اقوام ایرانی را در استانها و شهرستانهای مختلف کشور نشان میدهند. از جمله نکاتی که با نگاه به این نقشهها استخراج میشود میتوان به موارد زیر اشاره کرد [۷]:
- گویشوران زبانهای کاسپین شامل مازندرانی، گیلکی، تالشی و … بیش از همه در آبادیهای استانهای مازندران و گیلان غلبه دارند.
- گویشوران ترکزبان در درجه اول در شمال غرب کشور یعنی در آبادیهای استانهای آذربایجان شرقی، اردبیل و زنجان، برخی از همسایههای آنها مانند آذربایجان غربی، همدان، قزوین، استان مرکزی و در کنار آنها البرز و تهران، در درجه دوم در شمال شرق یعنی در آبادیهای استان گلستان (ترکمنها) و برخی از استانهای همسایه آن مانند خراسانی شمالی، و در درجه سوم در مرکز مایل به جنوب یعنی در استان فارس (ترکان قشقایی) و برخی از همسایههای آن سکنی دارند.
- گویشوران فارسیزبان بیشتر در آبادیهای مرکزی، شرقی و جنوبی مانند استانهای اصفهان، یزد، سمنان، خراسان، کرمان، هرمزگان و بوشهر غلبه دارند.
- گویشوران زبان کردی در آبادیهای استانهای کردستان و بعد در همسایههای آن مانند آذربایجان غربی، کرمانشاه، ایلام و همدان اکثریت دارند. تمرکزی در شمال خراسان (کرمانجها) و نقاط پراکندهای در قزوین، گیلان، تهران و مازندران نیز مشاهده میشود.
- گویشوران زبان بلوچی عمدتاً در آبادیهای استان سیستان و بلوچستان و مناطق مجاور آن در استانهای هرمزگان و کرمان اکثریت دارند. علاوه بر این تمرکزی از ایشان در استان خراسان و گلستان نیز دیده میشود [۸].
- گویشوران زبان لری بیشتر در آبادیهای استانهای کهگیلویه و بویراحمد و لرستان و پس از آنها در استانهای چهارمحال و بختیاری، خوزستان و ایلام اکثریت دارند.
- گویشوران عربزبان بیشتر از همه در آبادیهای استان خوزستان و تا اندازهای در استانهای فارس، بوشهر و هرمزگان به چشم میخورند.
- آبادیهای چندزبانه اغلب در نقاط تلاقی سکونتگاههای اقوام مانند برخی از مناطق بین مرکز و مرز و همینطور مناطقی مانند مرز استانهای کرمان و سیستان و بلوچستان به چشم میخورند.
توزیع جغرافیای اقوام ایرانی در نقشههای فوق با در نظرگرفتن زبان گویشوران در جمعیت روستایی ترسیم شده است. اما با توجه به اینکه بخش عمده جمعیت شهری در قرن اخیر از روستا به شهر مهاجرت کرده، توزیع قومیتها در کل جمعیت نباید تفاوت زیادی با توزیع اقوام در جمعیت روستایی در نقشههای ترسیم شده داشته باشد. به عنوان نمونه، با توجه به غلبه گویشوران زبان کردی در روستاهای شهرستان سنندج چندان دور از ذهن نخواهد بود اگر بگوییم جمعیت کردها در میان شهرنشینان سنندج نیز در اکثریت قرار دارد.
توسعه انسانی و وضعیت سواد
توسعه انسانی در کشورها به طور کلی در سه بُعد دانش و آگاهی، سلامت و رفاه به صورت زیر اندازهگیری میشود [۹]:
- دانش و آگاهی: متوسط سالهای تحصیل
- سلامت: متوسط امید به زندگی (طول عمر)
- رفاه: متوسط درآمد
وضعیت سواد خواندن و نوشتن نیز شاخصی است که در دسته دانش و آگاهی قرار میگیرد و اگرچه با متوسط تعداد سالهای تحصیل یکی نیست، اما بر آن تقدم دارد. تا سواد خواندن و نوشتن نداشته باشیم امکان تحصیل فراهم نمیشود. در این مطالعه برای بررسی تفاوتهای میان اقوام، صرفا روی نسبت جمعیتِ باسواد به کل جمعیت تمرکز شده است. [۱۰]
اکنون که به تصویری کلی از دادههای در دست و شاخصهای مورد نظر رسیدیم، میتوانیم به پرسشی که در ابتدا طرح شد، به صورت محدود و مشخص بازگردیم:
- آیا تفاوتی در وضعیت سواد قومیتهای مختلف در ایران وجود دارد؟
برای پاسخ به این سوال ابتدا نقشه سواد در شهرستانهای ایران را ترسیم میکنیم و سپس تلاش خواهیم کرد تا با مدلسازی آماری پاسخی روشمند برای پرسش مطرح شده ارائه کنیم. مقایسه آماری وضعیت سواد در میان اقوام ایرانی نه تنها از نظر توسعه انسانی بلکه به طور خاص از نظر ایجاد فرصتهای برابر یادگیری و عدالت آموزشی نیز از اهمیت زیادی برخوردار است.
نقشه سواد در ایران
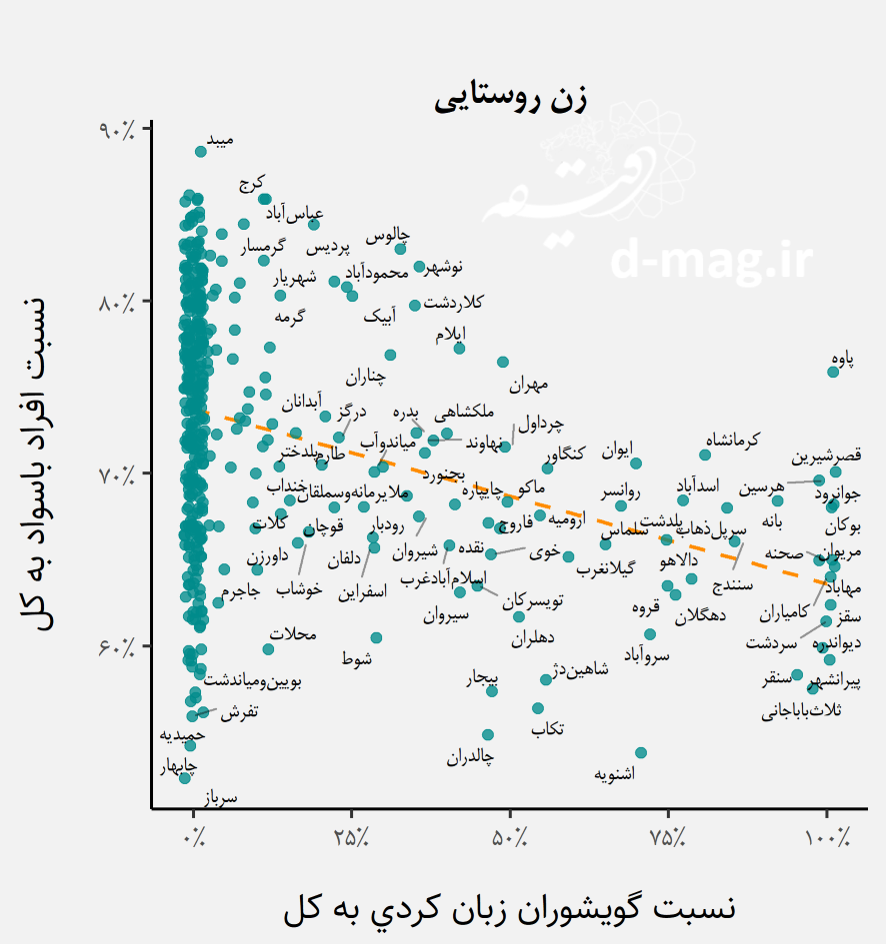
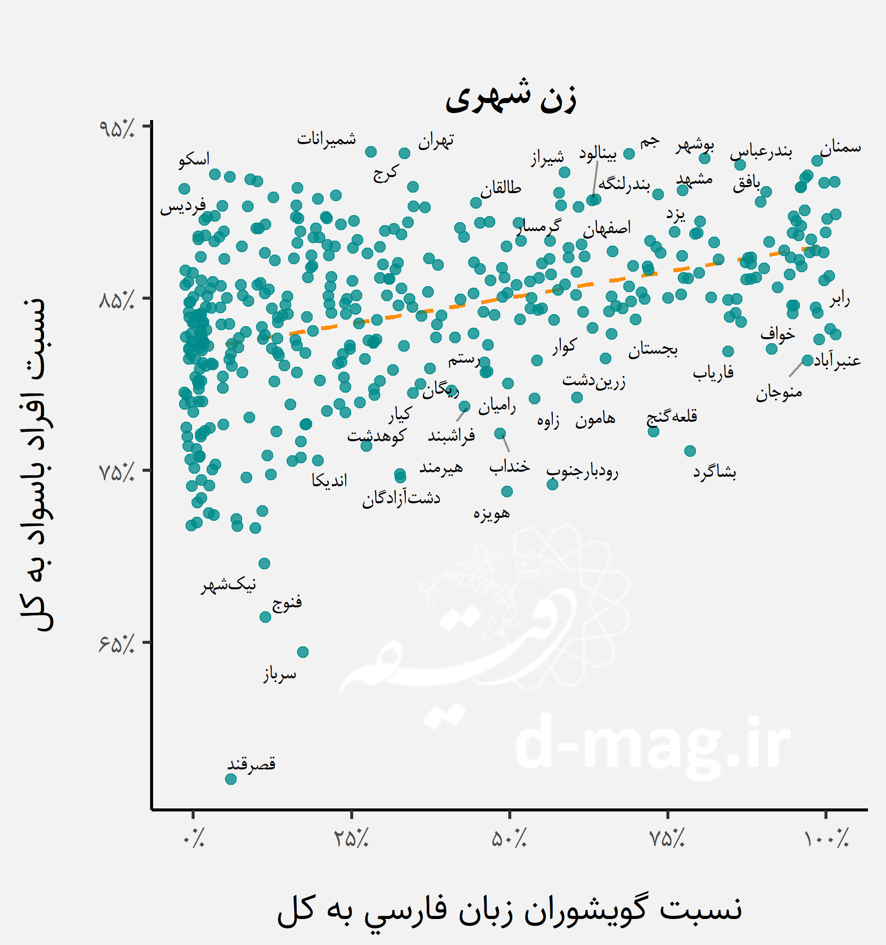
اگر توزیع جغرافیایی درصد جمعیت باسواد ایران بر اساس سرشماری مرکز آمار در سال ۱۳۹۵ را به تفکیک زن و مرد برای جمعیت شهری و روستایی ترسیم کنیم به نقشه زیر میرسیم.

ترسیم فوق نشان میدهد وضعیت سواد به طور کلی برای مرد شهری بهتر از سایر حالتها و برای زن روستایی بدتر از سایر حالتهاست. علاوه بر این، توزیع درصد جمعیت باسواد روی نقشه، شباهتهایی را با توزیع جغرافیایی گویشوران اقوام تداعی میکند که برای تحلیل دقیقتر آنها باید این دو داده را در یک مدل ساختاریافته آماری به صورت همزمان مورد بررسی قرار دهیم.
آیا تفاوت معناداری در وضعیت سواد اقوام وجود دارد؟
در یک وضعیت برابر و بدون تبعیض انتظار میرود با کم و زیاد شدن درصد جمعیت گویشوران هر یک از اقوام از کل جمعیت شهرستان، درصد افراد باسواد در شهرستان تغییری نکند. اما اگر رابطه معنادار بین قومیت و وضعیت سواد در دادههای گردآوری شده مشاهده شد، نمیتوان فرضیه عدم تبعیض را رد کرد؛ مگر اینکه پای عامل دیگری به میان بیاید که در صورت کمّیسازی باید با وارد کردن آن در مدل، تاثیر قومیت در مدل خنثی و فرضیه عدم تبعیض رد شود.
با استفاده از دادههایی که پیشتر معرفی شد، میتوانیم با مدلسازی آماری، تاثیر جمعیت هر یک از اقوام را در ارتباط با جمعیت باسواد شهرستان مورد بررسی قرار دهیم. ضرایب تاثیری که از نظر آماری معنادار باشند، بسته به مثبت یا منفی بودن مقدارشان به عنوان نوعی بهرهمندی نهادینه یا محرومیت سیستماتیک در وضعیت سواد اقوام تفسیر میشوند. نتیجه این مدلسازی برای جمعیت روستایی، شهری و کل جمعیت به تفکیک زن و مرد در قسمت زیر آمده است.
گزارش نتایج مدلسازی
نتایج شش مدل رگرسیون خطی جداگانه در جدول زیر قابل مشاهده است. با توجه به همبستگی جمعیت شهرستان با میزان توسعهیافتگی و امکانات آن، در این مدلها علاوه بر درصد گویشوران هر یک از زبانها، جمعیت شهرستان نیز به عنوان یکی از متغیرهای تبیینگر در مدلسازی وارد شده تا تاثیر سایر عوامل مرتبط با توسعهیافتگی که معمولا با جمعیت شهرنشین همبسته هستند تا حد امکان خنثی شود. نتایج نشان میدهد که از قضا تاثیر قومیت بر سواد در میان شهرنشینان نیز معنادار گزارش شده است[۱۱]. به بیان دیگر، هرچه جمعیت شهرنشین بیشتر باشد درصد جمعیت باسواد در کل شهرستان نیز بیشتر میشود. اما نکته حائز اهمیت اینجاست که جمعیت شهرنشین تنها عامل موثر بر وضعیت سواد نیست. درصد جمعیت گویشوران برخی از زبانها علی رغم لحاظ شدن عامل جمعیت شهرنشین همچنان معنادار است.

روش تفسیر نتایج
اعدادی که در جدول فوق گزارش شدهاند، ضرایبی برای بازگو کردن تاثیر جمعیت گویشوران هر یک از زبانها در وضعیت سواد شهرستان هستند. اگر p-value برای هر یک از آنها بیشتر از ۰.۰۱ باشد، مقدار به دست آمده در جدول درج نشده و معنای آن این است که رابطهای بین متغیر مربوطه و درصد افراد باسواد مشاهده نمیشود. ضریبِ به دست آمده تنها در صورتی گزارش شده که p-value کوچکتر از ۰.۰۱ باشد که معیاری نسبتا سختگیرانه در شناسایی روابط آماری است. اگر مقدارِ معنادارِ بهدستآمده منفی باشد با رنگ قرمز و اگر مثبت باشد با رنگ سبز مشخص شده است. در هر مدل ۹ متغیر مستقل و یک متغیر وابسته وجود دارد و مدلسازی به تفکیک وضعیت شهری و روستایی و کل و همینطور زن و مرد انجام شده است.
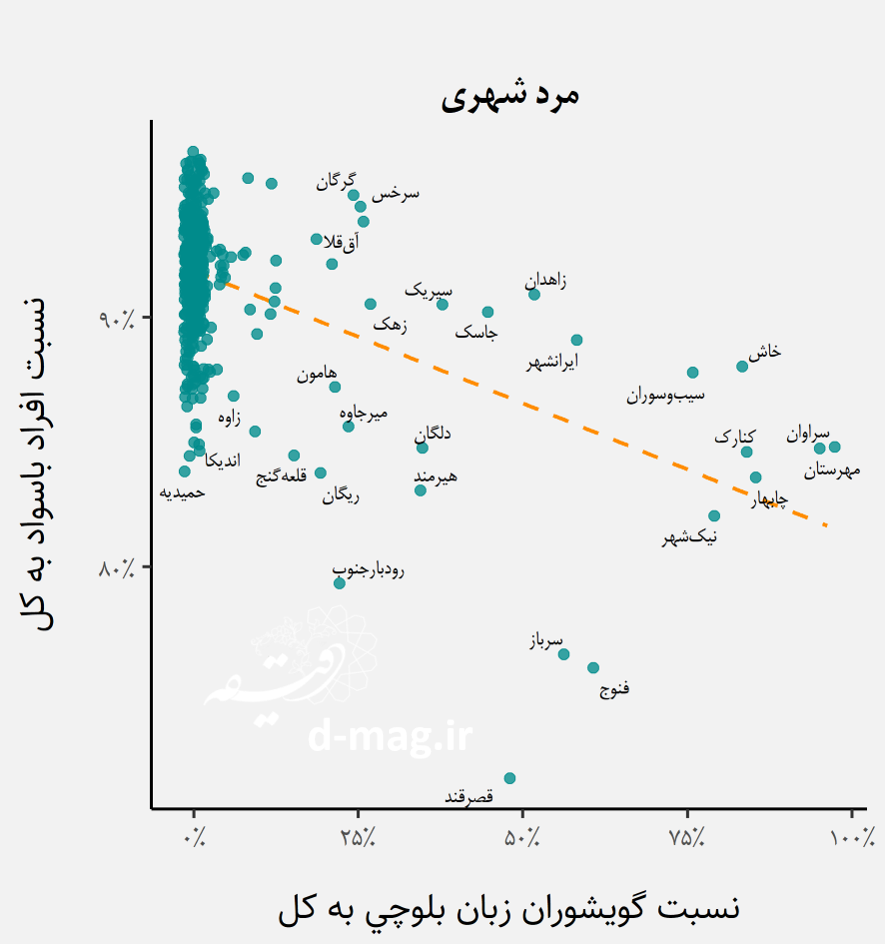
ضرایب گزارش شده در جدول نتایج روابط معنادار موجود میان متغیرهای تبیینگر مانند درصد گویشوران هر یک از زبانها روی درصد جمعیت باسواد را نشان میدهد. به عنوان نمونه ضریب تاثیر ۰.۲- که برای زنان روستایی بلوچ در جدول آمده بدین معناست که با فرضِ ثابت بودنِ تقریبیِ گویشوران دیگر زبانها، اگر تعداد گویشوران بلوچ یک واحدِ درصد در میان زنان روستایی شهرستانی افزایش یابد، انتظار میرود به طور متوسط ۰.۲ درصد از زنان روستایی باسواد شهرستان کم شود. به عبارت دیگر، رابطهای سیستماتیک به صورت تاثیر منفی بین قومیت بلوچ و عدم توسعه شاخص انسانیِ وضعیتِ سواد در میان زنان روستایی قابل مشاهده است. منظور از تاثیر منفی این است که هر چه جمعیت گویشوران یک زبان از کل جمعیت شهرستان بیشتر باشد، سهم افراد باسواد از کل جمعیت کمتر شود.
شاخصR۲ عددی بین ۰ و ۱ است و قدرت تبیین مدل را نشان میدهد. این شاخص برای هر مدل به صورت جداگانه گزارش شده است.
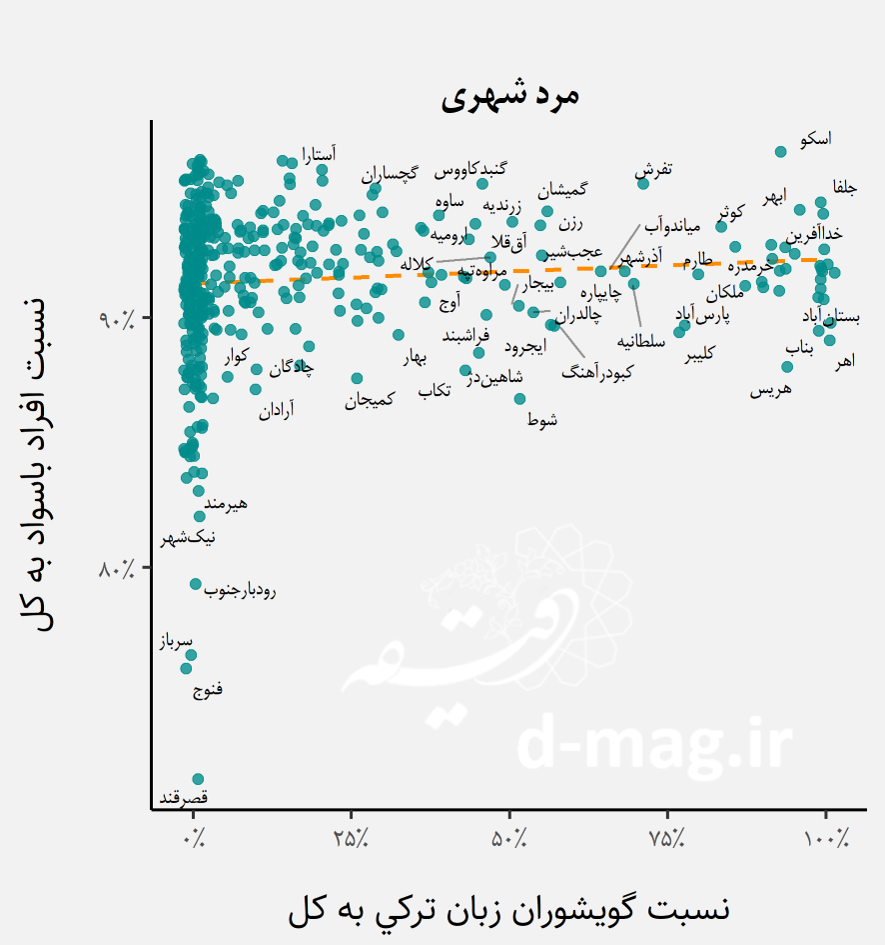
در میان گویشوران زبانهای فارسی و کاسپین و همینطور در میان جمعیت چندزبانه هیچگونه تاثیر معنادار منفی بر وضعیت سواد جمعیت کلی شهرستان مشاهده نمیشود، برعکس در برخی موارد مانند شهرنشینان فارسیزبان و کاسپین تاثیر مثبت معنادار مشاهده میشود. به بیان دیگر هرچه سهم فارسیزبانان و زبانهای کاسپین از کل جمعیت شهر در شهرستان بیشتر باشد به طور متوسط انتظار میرود وضعیت سواد شهرستان نیز بهتر باشد.
در مورد گویشوران بلوچ این وضعیت کاملا برعکس است و رابطه منفی بین سهم آنها از کل جمعیت و وضعیت سواد در شهرستان، بیشتر از سایر موارد دیده میشود. این رابطه با شدت کمتر، در مورد زن روستایی کرد، ترک، لر و عرب و همینطور زن شهری کرد و عرب مشاهده میشود. در میان مردان شهری غیر از مرد بلوچ رابطه معنادار منفی دیگری با وضعیت کلی سواد در شهرستانها دیده نمیشود. به بیان سادهتر، در میان مردان شهرنشین وضعیت سواد مردان بلوچ به طور متوسط از مردان دیگر پایینتر است. در وضعیت سوادِ دیگر مردان شهرنشین، تفاوتِ معنادارِ منفیِ دیگری میان اقوام مشاهده نمیشود. در میان مردان روستایی، علاوه بر مرد بلوچ، رابطه منفی معنادار در مورد مرد لر، کرد و ترک نیز با شدت کمتر قابل مشاهده است.
در ادامه چند نمونه از نمودارهای پراکندگی درصد گویشوران یک زبان برای نشان دادن سه حالت ممکن آورده شده است:
- فاقد رابطه معنادار به عنوان نمونه برای ترکزبانان در میان مردان شهری
- دارای رابطه معنادارِ مثبت به عنوان نمونه برای گویشوران فارسیزبان در میان زنان شهری
- دارای رابطه معنادارِ منفی به عنوان نمونه برای بلوچها و کردها در میان مردان شهری و زنان روستایی
در ادامه سعی میکنیم با وارد کردن متغیر سِنّ، رابطه قومیت و سواد را به تفکیک گروههای سِنّی مورد بررسی قرار دهیم.
وضعیت سواد و دلالتهای تاریخی
وضعیت سواد در ایران در قرن اخیر و در طی سالهای مختلف دستخوش تحولات زیادی شده است. به همین دلیل بهتر است آن را به تفکیک گروههای سِنّی نیز مورد بررسی قرار دهیم. اگر توزیعِ درصدِ افرادِ باسواد در شهرستانها را به تفکیک گروههای سِنّی و زنومرد برای جمعیت شهری و روستایی در سرشماری ۱۳۹۵ ترسیم کنیم، به نتایج زیر میرسیم (محور عمودی در مقیاس آزاد ترسیم شده و تفاوتی که در مساحتهای زیر نمودار به نظر میرسد چیزی را نشان نمیدهد):

چنانچه مشاهده میشود، درصد افراد باسواد از کل جمعیت با تغییر گروه سنی به شدت تغییر میکند (نگاه کنید به تفاوت قلههای آبی و نارنجی در دستههای مختلف). به عنوان نمونه، درصد باسواد در میان کودکان و نوجوانان به مراتب بیشتر از گروههای مسنتر است. کاهش افراد باسواد با افزایش سن در جمعیت شهری و روستایی و از آن مهمتر در میان زن و مرد کاملا مشهود است. به همین سبب لازم است بررسی رابطه قومیت و وضعیت سواد را علاوه بر تفکیک زنومرد و شهری و روستایی، به تفکیک گروه سنی نیز انجام دهیم.
رابطه قومیت با وضعیت سواد در گروههای سنی
با توجه به اینکه برآوردی از درصد گویشوران هر یک از زبانها از یک سو و درصد افراد باسواد در جمعیت روستایی و شهری هر شهرستان را از سوی دیگر در اختیار داریم میتوانیم رابطه آنها را به تفکیک زنومرد و گروه سنی مورد بررسی قرار دهیم. این رابطه میتواند در گروههای سنی مختلف متفاوت باشد. به عنوان نمونه، در جمعیت زنان در گروه سنی ۳۵ تا ۳۹ سال که گروه سنی جوانتری محسوب میشود، با افزایش درصد گویشوران زبان ترکی در جمعیت روستایی، تغییر معناداری در درصد افراد باسواد مشاهده نمیشود (نگاه کنید به شکل زیر)، در حالیکه مطابق نتایج به دست آمده زن روستایی ترک جزو مواردی بود که رابطه معنادار منفی بین قومیت و وضعیت سواد آن گزارش شده بود.

در برخی موارد نیز رابطه در بعضی گروههای سنی در مقایسه با آنچه در کل مشاهده شد شدیدتر و شیب خطچین برازششده تندتر به نظر میرسد. به عنوان نمونه در گروه سنی ۴۵ تا ۴۹ سال در جمعیت زنان روستایی با افزایش تعداد گوریشوران زبان عربی، درصد افراد باسواد در شهرستانها کم میشود (نگاه کنید به شکل زیر و شیب قابل توجه خطچین).

برای اینکه بتوانیم متغیرهای فوق را در کنار یکدیگر مورد تحلیل قرار دهیم، رابطه درصد جمعیت گویشورانِ زبانهای مختلف را با درصد افراد باسواد در شهرستانها در قالب مدلهای رگرسیون خطی متعدد برای گروههای سنی مختلف و همینطور برای زن و مرد و جمعیت شهری و روستایی به صورت جداگانه مورد بررسی قرار دادیم[۱۲].
گزارش و بررسی نتایج مدلسازیها
نتایج مدلسازی به تفکیک گروههای سنی و زن و مرد در سه جدول زیر به برای جمعیت روستایی، شهری و کل جمعیت آمده است[۱۳].



در متولدین سالهای پایانی قرن ۱۳ و ابتدای قرن ۱۴ شمسی، در میان زنان و مردان شهری و روستایی هنوز تفاوت چندانی بین وضعیت سواد اقوام مشاهده نمیشود. اگر بخواهیم آمار گروههای سِنّی سرشماری ۹۵ را به عنوان مبنایی اولیه برای برداشتهای تاریخی به کار ببندیم، به نظر میرسد در میان متولدین سالهای بعدی – یعنی تقریبا همزمان با پروژه توسعه در زمان پهلوی اول و دوم – تفاوتهایی در وضعیت سواد در اقوام بلوچ، کرد، عرب و لر به وجود آمده و چند دهه ادامه یافته است چرا که در شهرستانهایی که جمعیت این اقوام بیشتر بوده درصد جمعیت باسواد کمتر بوده است.
اگر بلوچ، عرب، ترک، لر یا کرد بودن در برخی از گروههای سِنی در میان زنان یا مردان تاثیر منفی بر وضعیت سواد جمعیت داشته، در میان گویشوران زبانهای فارسی و کاسپین و تا حدی در میان ترکزبانان این رابطه کاملا برعکس است. در بسیاری از گروههای سنی رابطه گویشوران زبان فارسی و زبانهای کاسپین با وضعیت سواد مثبت است و با افزایش جمعیت آنها وضعیت سواد در کل جمعیت بهتر میشود. این رابطه از گروههای سنی بیش از ۷۰ سال یعنی در میان متولدین قبل از دهه ۲۰ آغاز میشود و تا متولدین دهههای ۶۰ تا ۸۰ شمسی یا حتی تا زمان سرشماری (۱۳۹۵) ادامه پیدا میکند.
در مجموع به نظر میرسد توسعهای که در دوره پهلوی آغاز شده و در دهههای بعد ادامه یافته با توزیع اقوام در جغرافیای جمعیتی کشور بیارتباط نبوده است.
تاثیر منفی افزایش جمعیت لر و کرد بر وضعیت سواد نیز بعد از چند دهه متوقف میشود و در میان متولدین دهه ۳۰ و جوانتر، رفتهرفته دیگر اثری از آن دیده نمیشود. برخی از این روابط در دوران پهلوی دوم و برخی در زمان جمهوری اسلامی از بین میروند. از تاثیر مثبت درصد جمعیت فارسیزبان و کاسپین در وضعیت سواد کل جمعیت نیز به مرور کاسته میشود و در میان متولدین دهههای اخیر دیگر اثری دیده نمیشود.
آنچه بیشتر از همه نکات یاد شده در نتایجِ به دست آمده اهمیت دارد، روابط معناداری است که تا زمان حاضر نیز ادامه یافته و هنوز از بین نرفتهاند. این موارد عبارتند از تاثیر منفی افزایش جمعیت مردم بلوچ و زنان روستایی عربزبان بر وضعیت سواد آنان در کل جمعیت. به عبارت دیگر، شهرستانهایی که درصد مردم بلوچ در آنها – چه در میان مردان و چه در میان زنان – بیشتر است، به طور متوسط از نظر سواد وضعیت پایینتری نسبت به سایر شهرستانها دارند. این رابطه در مورد زنان روستایی عربزبان نیز به همین صورت وجود دارد. تبعیض اشاره شده در مورد مرد و زن بلوچ و زنان روستایی عربزبان از گروه سنی ۳۵ تا ۵۴ سال (در سال ۹۵) یعنی در میان متولدین ۴۰ و ۵۰ به مرور شروع به کاهش کرده و در دهههای بعد نیز ادامه یافته است. با این حال شواهد این تحقیق حاکی از این است که تبعیض در میان مردان و زنان بلوچ و زنان روستایی عربزبان همچنان وجود دارد.
لازم به ذکر است که در مورد زنان روستایی عربزبان در جوانترین گروه سنی یعنی در گروه سنی ۶ تا ۹ سال یعنی متولدین نیمه دوم دهه ۸۰ این وضعیت نسبت به متولدین دهه ۷۰ و متولدین نیمه اول دهه ۸۰ دوباره تشدید شده که توضیح چرایی آن نیازمند بررسیهای بیشتر و پژوهشهای جدیدتر است.
نتایج به دست آمده درباره گروههای جوانتر در مقایسه با گروههای مسنتر قابل اتکاتر است. هنگام تحلیل وضعیت سواد در گروههای مسنتر، تاثیر عوامل دیگر نیز بیشتر میشود و برداشتهای تاریخی درباره متولدین دهههای مختلف را با چالش مواجه میکند. مثلا ممکن است بخشی از آنها قبل از سال ۹۵ از دنیا رفته باشند و اطلاعات آنان در سرشماری ۱۳۹۵ مرکز آمار موجود نباشد. هر چه به سمت گروههای مسنتر میرویم این سوگیری به صورت نسبی بیشتر میشود. به عنوان نمونه، ممکن است کسانی که پا به سن گذاشتهاند و در سرشماری ۱۳۹۵ به اطلاعات آنان دسترسی داریم، نسبت به متولدین همسن و سال خود از تحصیلات بیشتری برخوردار باشند. چون جمعیت باسواد و تحصیلکرده احتمالا از بخش برخوردارتر جامعه بوده و به خدمات بهداشتی و تغذیه بهتری دسترسی داشته و در نتیجه احتمالا از امید به زندگی بالاتری برخوردار بوده است.
برای حصول اطمینان بیشتر در برداشتهای تاریخی و جلوگیری از این دست سوگیریها لازم است سرشماریهای قدیمیتر نیز مورد بررسیهای مشابهی قرار گیرند.
نتیجهگیری
سواد به عنوان یکی از اساسیترین شاخصهای توسعه انسانی، در میان قومیتهای ایران وضعیتی یکسان ندارد. این شاخص به طور کلی در میان شهرنشینان و مردان وضعیتی بهتر دارد. در میان مردان شهری تنها مرد بلوچ است که به صورت نهادینه از بیسوادی رنج میبرد. در میان زنان شهری علاوه بر زن بلوچ، این وضعیت برای زن کرد و عرب نیز قابل مشاهده است، در میان مردان روستایی این وضعیت علاوه بر مرد بلوچ، برای مرد لر، ترک و کرد نیز مشاهده میشود و در میان زنان روستایی این وضعیت علاوه بر زن بلوچ، برای زن کرد، عرب، لر و ترک نیز دیده میشود.
وضعیت سواد ایرانیان در صد سال اخیر تغییرات زیادی داشته است. این را میتوان از نسبت جمعیت باسواد در گروههای سنی مختلف در آخرین سرشماری آشکارا مشاهده کرد. اگرچه وضعیت متمایز سواد اقوام همچنان در جمعیت کنونی کشور قابل مشاهده است، اما در برخی از قومیتها مانند کرد و لر در آخرین سرشماری مرکز آمار ایران در سال ۱۳۹۵ اثری از این تمایز در گروههای سِنّی جوانتر دیده نمیشود. اما در بعضی از اقوام مانند مردم بلوچ، وضعیت سواد از دهههای گذشته تاکنون به صورت معناداری از دیگر اقوام پایینتر بوده است. از این پدیده میتوان به عنوان طولانیترین نمونه تبعیض در میان موارد بررسیشده یاد کرد. مشابه این تبعیض کموبیش برای زنان روستایی عربزبان نیز وجود دارد.
نابرابری در وضعیت سواد برای مردم بلوچ و همینطور زنان عرب اگرچه در نیم قرن اخیر کاهش یافته اما همچنان قابل مشاهده است. در مورد زنان عرب وضعیت بیسوادی بعد از چهار دهه کاهش، در میان متولدین نیمه دوم دهه هشتاد دوباره افزایش یافته است. مطابق با آخرین اطلاعاتی که میتوان از سرشماریهای مرکز آمار در ۱۳۹۵ دریافت کرد، این تنها مورد تشدید وضعیت بیسوادی در میان اقوام ایران به تفکیک زن و مرد در جمعیت شهری و روستایی در زمان حاضر است.
به عنوان قدم بعدی این مطالعه لازم است روی شناسایی عوامل موثر در وضعیت سواد در میان مردم بلوچ و زنان روستایی عرب تمرکز شود و عواملی مانند عدم دسترسی به مدرسه، چشماندازهای نامناسب شغلی، ترس از خدمت سربازی، ازدواجهای زودهنگام و … به منظور رفع آنها مورد بررسی قرار گیرد.
ارجاع و پانویس
[۱] بررسیهای مرکز پژوهشهای مجلس نشان میدهد که بازماندن از تحصیل از ۷۷۸ هزار نفر در سال ۱۳۹۴ به ۹۱۱ هزار نفر در سال ۱۴۰۱ رسیده و ۱۷% افزایش داشته است. مطابق همین گزارش پنج استان سیستان و بلوچستان، خراسان رضوی، تهران، خوزستان و آذربایجان غربی دارای بیشترین فراوانی مطلق بازماندگان از تحصیل هستند. همچنین استان های سیستان و بلوچستان، خراسان رضوی، خوزستان، آذربایجان غربی و کرمان نیز به ترتیب دارای بیشترین آمار تارکان از تحصیل در سال ۱۴۰۱-۱۴۰۰ هستند (مرکز پژوهشهای مجلس دی ماه ۱۴۰۱).
[۲] رئیس سازمان ثبت احوال در سال ۱۴۰۱ گفت پنج استانِ سیستان و بلوچستان، خراسان، گلستان، کرمان و آذربایجان غربی بیشترین آمار افراد بی شناسنامه را در سطح کشور دارند (خبرگزاری مهر). مطالب دیگری نیز وجود دارد که تعداد بیشناسنامهها را بیش از یک میلیون نفر برآورد میکند و بیشترین تعداد آنها را در سیستان و بلوچستان گزارش میکند (به عنوان نمونه نگاه کنید به گزارش ایسنا در دی ۱۴۰۰)
[۳] نتایج سرشماری عمومی نفوس و مسکن (+)
[۴] اطلس ایران (ایران کارتو)؛ محصول همکاری مشترک علمی میان پژوهشگران ایرانی و فرانسوی در چارچوب تیم تحقیقاتی علوم اجتماعی جهان معاصر ایران (جهان ایرانی CNRS)، محمود طالقانی، برنارد هورکارد و هوبر مازورک؛ ترجمه دکتر سیروس سهامی با همکاری دکتر محمد حسین پاپلی یزدی؛ موسسه امیرکبیر، مشهد ۱۳۷۶ (+)
[۵] زبانهای حاشیه دریای خزر مانند گیلکی، تالشی و مازندرانی (+)
[۶] دهستانهایی که غلبه با یک زبان نباشد «چندزبانه» در نظر گرفته شدهاند.
[۷] جمعیت گویشوران یک زبان ممکن است با جمعیت قومیت مربوط به آن برابر نباشد – مثلا ممکن است یکی از اعضای قوم نتواند به زبان قوم خود صحبت کند – با این حال این دو عبارت در نوشتار حاضر عملاً هممعنی در نظر گرفته شده و گاهی به جای یکدیگر به کار رفتهاند.
[۸] مهاجران بلوچ استان گلستان (ایسنا)
[۹] Human Development Index (HDI), United Nations Development Programme (UNDP)
[۱۰] تعاریف و مفاهیم استاندارد آماری، ویرایش سوم ۱۳۹۳، صفحه ۴۳۲ (مرکز آمار ایران)
[۱۱] جمعیت در مقیاس لگاریتم پس از تفاضل از میانگین و تقسیم بر انحراف معیار در ۱۰۰ ضرب شده تا با مقیاسی مشابه دیگر متغیرها به صورت واحد درصد در مدل وارد شود.
[۱۲] مشابه مدلسازی قبلی، در این مدلسازی نیز هر یک از مدلها از ۹ متغیر تبیینگر (۸ عدد بعنوان برآورد درصد گوریشوران هر یک از گروههای زبانی یادشده و لگاریتم جمعیت نرمال شده ضرب در ۱۰۰) و درصد افراد باسواد شهرستان به عنوان متغیر وابسته تشکیل شدهاند.
[۱۳] با توجه به این که آزمون فرضهای متعددی در این مدلسازیها انجام شده (۳۶۰ مورد برای وضعیتهای روستایی و شهری و کل: در مجموع ۱۰۸۰ مورد) و نتایج به صورت توامان مورد تحلیل قرار میگیرد، لازم است به دو نکته توجه شود. اول آنکه مرز p-value برای معناداری تا آنجا که ممکن است بزرگ انتخاب نشود (در این مطالعه به طور کلی از p-value < 0.01 برای گزارش روابط معنادار استفاده شده است). دوم اینکه در تحلیل نتایج به جای تکیه بر یکی از مقادیر، الگوهای قابل مشاهده در مجموعهای از مقادیر تحلیل و تفسیر شود.
مطالب مرتبط






نویسندگان

دانشآموختۀ آمار و تحلیلگر داده





دانشجوی جامعهشناسی و تحلیلگر داده






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
4 پاسخ
عالی بود
سلام در نقشه ترکی محلات رو کم رنگ گذاشتید من بعنوان یک محلاتی تا بحال در این شهرستان ترک ندیدم، لطفاً دقیق تر دسته بندی کنید🙂🙏🏻
بسیار قوی و منسجم بود
تا به حال کاری به این قوت درباره قومیتها در ایران نخونده بودم.
از زحمات گرانقدرتان تشکر می کنم.